

Lemmatization and stemming. When building a text classificatory, there is no sense in dividing the forms (noun declension, verb conjugation) of the same word. It will lead to unreasonable dictionary growth, statistics fragmentation, resource intensity growth and model quality decrease.
Lemmatization is a revaluation of each word in the document to its normal (infinitive) form. There are special lemmatizer tools based on the storage of a grammar vocabulary with all word forms. The pitfall of the lemmatization is the labor intensity for creating these vocabularies and, as a consequence, their insufficiency, especially regarding the special terminology and neologisms, which are most needed for thematic modelling.
Stemming is a simpler technology that lies in casting out the changeable word parts, mainly, flections. It does not require dictionary storage of all words and is based on the linguistic morphology rules. The pitfall of the stemming is a larger errors quantity. Stemming suits best for the languages like English, but is worse for fusional languages.
Deleting of stop-words. Words that are sometimes met in various thematic texts, are often not needed in a classification process, and could be casted out. Those could be prepositions, conjunctions, numeral adjectives, pronouns, some verbs, adjectives and adverbs. The number of such words usually varies up to several hundreds. The casting out of such words does not affect the dictionary length, but could lead to a significant decrease in some texts’ length.
Casting out of rarely used words. Words that are met in a long text far too rarely, for example, just once, could be also casted out, assuming that these words do not have major meaning or any significant influence in this particular text.
Key phrases extraction. When processing collections of scientific, legal or other special texts we can sometimes выделяют key phrases instead of separate words. Those are word collocations, that are chunks of language or terms in a particular industry. This is a separate and very complex task that could be solved by machine learning techniques with involving ML experts to form learning samples and to control the quality of automatic terms extraction.
Let’s assume that a dictionary W has been created as a result of preprocessing of all documents from the collection D and could contain both separate words and key phrases. The dictionary elements t ∈ W we shall call «terms».
VECTOR LAYOUT OF THE DOCUMENT
Let’s consider one of the most popular methods of document layout in tasks that are connected with information search – the vector model of the document. In a vector model, every document is seen as a vector that consists of real numbers. Thanks to this factor, to classify documents we can use methods for operating real numbers vectors.
Let’s assign every document with its vector that has the length of the vocabulary|W|:
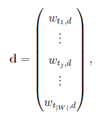
Here, wtj ;d — term value — is some number that depends on the number of term occurrence tj ∈ W in d and describes the “importance” of the tj term for understanding, to which class text d relates. The value document alignment to the terms is called evaluation, and the rules of this alignment are called evaluation schemes.
Let’s consider some evaluation schemes.
Evaluation scheme tf. Let’s assign some value to each term that is met in the document. This value will depend on the number of this term occurrence in this document. If we assign the term value equal to the number of this term (t) occurrence in the document d, then we will receive the evaluation scheme that is called term frequency and is denoted as tft,d, whereas the index t stands for term, and index d stands for the document.
Frequency in cf collection and reverse documentary frequency idf. Such calculation of the term frequency has one major pitfall: all the terms are considered equally important. Let’s consider an example. The text collection about automotive industry contains the word “automobile” in almost any document. And though this term will have high frequency characteristics, when rubricating this collection, it will not have any significant importance. To eliminate this pitfall, we can calculate the frequency for each term in the collection cf, which means a general quantity of the term evaluation in all documents of the collection, and decrease the tf value for the terms with high frequency in the collection.
Also, to eliminate this pitfall, we can use the documentary frequency df that is represented by the number of documents in the collection, that contains t term.
Let’s assign N as a number of documents in the D collection. Let’s define the reverse documentary frequency of the t term as following:
![]()
Thus the reverse documentary frequency of the rarely met term is large, whereas for the often met term it’s relatively small.
The evaluation scheme tf-idf. By combining the term frequency in the tf document and the reverse documentary frequency, we can receive the evaluation scheme tf-idf:
![]()
The value tf-idf of the t term in the d document has following characteristic:
- It reaches its peak (max value), if the t term is met many times in a smaller quantity of the documents (thus intensifying them as opposite to the other documents)
- It decreases, if the term is met in one document several times only, or in many documents.
- It reaches its peak (max value), if the term is met in almost all documents.
Here we should note that in case if the term is not met in the document, its tf-idf value in this document equals to zero.
…Would you like to learn more?.. Stay tuned for our next articles on Natural Language Processing at Mellivora Software’s blog!
Chalk and talk session by Mellivora’s NLP expert Olga Kanishcheva, a PhD in Computer Science of the Intellectual Computer Systems and a lecturer at Kharkiv Polytechnic Institute.